
A brief history of speech to text + how it actually works
The computer is listening... or rather, it's trying. 💻👂

Hello from the snowy Western US! I spoke this sentence to the computer, and it turned it into this text using speech to text. Let’s dive in…
Speech to Text, also known as Automatic Speech Recognition (ASR), is the task of taking human speech and turning it into computer text.
‘Talking to the computer’ is a classic item in science fiction, and humans have been working on machines that can understand human speech for over 70 years.
Amazingly, the dream of Star Trek has become real, with speech-to-text software progressing from buggy research projects, to high-end expensive software, to everywhere, included for free on every phone and computer.

Progress from the first speech to text system in 1952 has not been linear, and new AI methods are making speech to text faster, cheaper, and more available than ever before.
I had to break this email into two, because there is just so much to learn and talk about!
In today’s episode we will cover:
A brief history of speech to text
How speech to text actually works
In part 2 (read it here), we covered how to actually use speech to text with:
3 of the best speech to text apps
9 open source speech to text models you can build into products for free
9 paid APIs if you don’t want to fuss with installing software
Let’s start by jumping back to the 1950’s.
A brief history of speech to text
1950’s
Computers were huge, slow, and expensive in the 50’s.
In 1951 The Univac 1, the first commercial computer to attract widespread public attention, was created by Presper Eckert and John Mauchly. The Univac 1 used 5,200 vacuum tubes and weighed 29,000 pounds. Eventually, 46 Univac 1s were sold at more than $1 million each.
The next year in 1952, Bell Laboratories created the “Audrey” system. Audrey was the first known and documented speech recognizer. Audrey could recognize strings of spoken digits if the user paused in between. It also took up a large portion of a room with its racks and processing units. It has accuracy rates of up to 90% if the user trained it, but dropped to 70-80% for users it didn’t recognize.
Audrey’s purpose was to help toll operators connect more phone calls, but the high cost and inability to recognize a wide array of voices meant it failed its commercial use case.

1960’s
In 1962 IBM introduced “Shoebox” which was a voice controlled calculator. It understood and responded to 16 words in English, numbers and operators, and could do simple math calculations by feeding the numbers and operators (add, subtract) it recognized to an external adding machine which would print the response. Shoebox was operated by a microphone converting voice sounds into electrical impulses which were classified according to various types and acted on.

There were other speech to text efforts in the US, the UK, and the Soviet Union. But all these early systems were based on matching individual words against stored voice patterns which was difficult and expensive.
1970’s
Meaningful advancements in speech to text happened in the 1970s.
In 1971, the US Department of Defense’s research agency DARPA funded five years of a Speech Understanding Research program, with the goal being a creation of a system with a minimum vocabulary of 1,000 words.
IBM, Carnegie Mellon University, and Stanford took part in the DARPA program. The program was one of the largest in the history of speech recognition. And it resulted in Harpy, the most advanced speech to text system of the time.
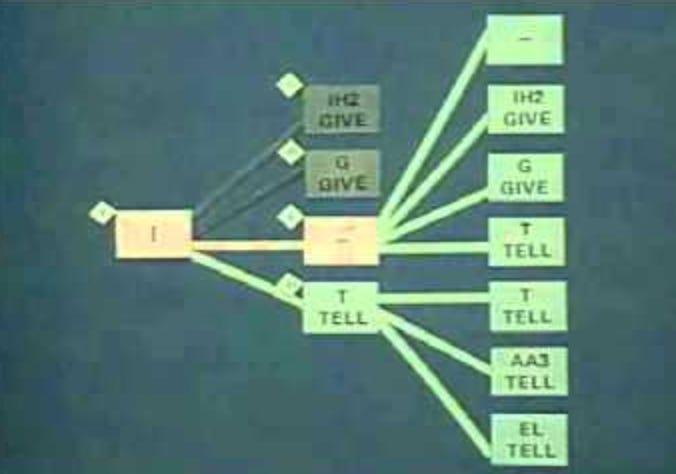
Carnegie Mellon’s “Harpy’ speech system was capable of understanding over 1,000 words, which is about a three-year-old’s vocabulary. Harpy was the first speech to text system that used a language model to determine which sequences of words made sense together which reduced errors.
1980’s
The ‘80s saw speech recognition vocabulary go from Harpy’s 1,000 words to several thousand words.
In the mid 1984 IBM built a voice activated typewriter dubbed Tangora, capable of handling a 20,000-word vocabulary. IBM’s jump in performance was based on a hidden Markov model.
The hidden Markov model estimated the probability of the unknown sounds actually being words, instead of just matching words to sound patterns. The method predicts the most likely words which follow a given word.
For example “This charming gentleman” is statistically more likely to be a phrase than “This charming pineapple”.
Like all the systems before, each speaker had to individually train the typewriter to recognize his or her voice, and use discrete dictation, meaning the user had to pause… after… every… word. Still, Tangora represented the very best and most expensive speech to text system of that time.
On the other end of the spectrum, very primitive speech recognition systems continued to get cheaper, showing up in novelty use cases. In 1987, the doll Julie by Worlds of Wonder, could recognize specific words like ‘play’ or ‘hungry’.
1990’s
In the 1990’s speech recognition moved out of research projects and novelty uses and into business use cases.
The rise of the personal computer continued to propel speech recognition forward. This decade was the real start of an entire speech recognition industry with companies like Nuance, and SpeechWorks joining BellLabs, IBM, and Dragon.
In 1990, Dragon released the first consumer speech recognition product, Dragon Dictate, which cost a stunning $9,000.
On the corporate side, BellSouth introduced the voice portal (VAL) in 1996. The first dial-in interactive voice recognition system, this system gave birth to the (often hated) phone tree systems that are still used today.
Faster processors and larger storage mediums helped increase speech to text capabilities and in 1997, Dragon released Dragon NaturallySpeaking, the first continuous speech recognition product that didn’t require users to pause… after… every word.
Accuracy continued to improve, but all the systems still required each user to train the system, and speech recognition as a whole acquired a jaded reputation as being ‘not good enough’ for normal usage.
2000’s
By the year 2001, speech recognition technology had achieved close to 80% accuracy but progress was slow until Google arrived with the launch of Voice Search.
1-800-GOOG-411 was a free phone information service that Google launched in April 2007. It worked just like 411 information services had for years—users could call the number and ask for a phone book lookup—but Google offered it for free.
They could do this because no humans were involved in the lookup process, the 411 service was powered by voice recognition and a reverse text-to-speech engine.
Google’s breakthrough was to use cloud computing to process the data instead of processing it on a device.
This meant the app had massive amounts of computing power at its disposal instead of a single computer, and Google was able to run large-scale data analysis for matches between the user's words and the huge number of human-speech examples it had amassed from billions of search queries.
This allowed speech to text models to understand any user, without the user having to train the system on their voice specifically.
Google put this service into the Google Voice Search app for iPhone in 2008.
Biggest data sets, more computing power, and using neural networks started to improve accuracy rates and decrease costs.
2010’s
The 2010’s were the decade of voice assistants.
In 2010, Voice Actions launched on Android Market and allowed users to issue voice commands to their phone.
Apple launched Siri in 2011. Amazon released Alexa, and Microsoft released Cortana in 2014. Google Home came out in 2016.
Large tech companies continued to work on research projects and new models which achieved ever-increasing accuracy rates. In 2016 IBM had the top mark with a word error rate of 6.9 percent. In 2017 Microsoft beat IBM with a 5.9 percent claim. IBM quickly improved its rate to 5.5 percent.
With increasing accuracy and failing costs, many commercial speech to text APIs came out (more about those in part 2).
Google released their Speech-to-Text v1 API in 2017, and Amazon launched Amazon Transcribe the same year.
The deep learning (bigger neural networks) era for speech-to-text started in 2017 when Baidu introduced the DeepSpeech paper. In 2017, Mozilla created an open-source implementation of the Baidu paper and released Mozilla DeepSpeech as open-source.
2020’s
Deep learning and machine learning techniques continue to decrease the cost, and increase the capability of speech to text.
OpenAI made a stir when it released Whisper as open source in 2022. Other models perform more accurately in certain contexts, Whisper can recognize and convert 99 different languages to English text, and can recognize different speakers and give timecodes of the resulting text.
Now, let’s open up the box and see how speech to text systems work.

How speech to text works
There are three main steps in a speech to text process.
Record analog speech into a digital audio file
Breaks the digital audio down, into individual sounds or chunks
Uses algorithms and models to find the most probable words from those chunks and outputs those words in text format.
So to complete Step 1, we need to capture a pressure wave.
Step 1 - Record digital audio
A sound is a vibration or pressure wave that moves through a transmission medium such as a gas, liquid, or solid. The transmission medium is usually air.
To digitally record the sound, a computer captures how much pressure there is over time. The measurement of pressure is taken thousands of times a second. For good-quality audio, 44,100 samples are taken every second.
If you look at it as a graph, the pressure of the wave is the Y axis, and the sample timing is the X axis.

Recording audio into a digital format doesn’t require AI. We have had digital audio for a while now with digital recording pioneered in Japan by NHK and Nippon Columbia in the 1960s. Once we have the digital sound files, we need to process them to separate them into usable chunks.
Step 2 - Break down audio into individual sound chunks
Digital audio files are just a bunch of binary numbers (011010101010110001), which represent the characteristics of the pressure wave at different points in time.
To turn audio into sound chunks, the system implements a frequency analysis.
Speech to text systems often filter the audio to distinguish the relevant sounds from the background or other noise.
One way to analyze the audio is to visualize the audio file by using a log mel spectrogram. A spectrogram is a visual representation of the characteristics of the sound, as it varies with time.
A common format for a spectrogram is a graph with two dimensions: one X axis represents time, and the other Y axis represents frequency; a third dimension indicating the amplitude (energy or loudness) of a particular frequency at a particular time is represented by the brightness or color.


You can also visualize the amplitude by using 3d height of each point in the image.

The system then looks at these images of the audio and separates the audio into chunks. This can be done by modeling the spectrogram mathematically as a waveform frequency vector. This is one number that represents the information contained in that chunk of audio data. By comparing the various vectors of different chunks, the system can accurately separate the audio into hundredths or thousandths of seconds pieces, and each chunk is then matched to a sound or phoneme.
A phoneme is a unit of sound that distinguishes one word from another in any given language. For example, there are approximately 44 sounds or phonemes in the English language.
An example of a phoneme is Phoneme 37 which is written in symbol form as ‘aʊ’. Phoneme 37 is the ow, ou, ough, sound, like in ‘now, shout, bough’.
Phonemes are used in speech-to-text systems because they represent the smallest unit of sound in a language.
In contrast, letters represent written symbols, not necessarily sounds. In many languages, the same letter can represent different sounds or combinations of sounds. For example, the letter "c" can be pronounced differently in the words "cat," "cent," and "cello." This variability makes it more difficult to accurately transcribe spoken words into text using letters alone, so we use the more specific and accurate phoneme.
When we speak, we produce a pressure wave vibration which is composed of a sequence of phonemes that form words and sentences. Our system has captured the pressure wave, visualized the sounds, and separated them into a sequence of phonemes.
Now we need to figure out what words are created by the sequence of phonemes. For this, we need to use math.
Step 3 - Use algorithms and models to find the most probable words from the sounds
This sequence of phonemes or sounds, is then run through an AI model that matches the pieces of words to sentences, words, and phrases. It makes predictions what the correct text is, and outputs the text.
AI uses the order, combination, and context of these phonemes to figure out what the speech is saying.
For example, ‘eight’, and ‘ate’ are made up of the same three phonemes: /eɪt/.
By looking at the phonemes that surround it, the AI can figure out which word you actually meant.
This is the hardest step in speech to text.
The reason is humans talk very differently, and mean the same thing. More than text, speech sounds vary greatly based on regional dialects, speed, emphasis, even social class, and gender. This is why all the early speech to text systems had to be trained to each individual speaker and suffered more errors.
Humans will mean the same thing, but make sounds at different speeds, leave out certain sounds, slur, chop and stutter. Background noise can hide or cover certain sounds. The location of the microphone to the user’s vocal cords can change the sounds. Dragon software still has entire help articles about how to place your microphone.
Let’s use an example. Since phoneme symbols are difficult to write and recognize, (what does /eɪt/ even mean) let’s use letters.
You are playing the role of AI. You have been given a digital audio file and are requested to output the text it contains.
We visualize the audio using a spectogram, and then break that audio file down into different sound chunks.
The sequence of sounds is: ‘totoihaveafeelingwerenotinkansasanymore’.
What would you predict the text would be?
If you predicted ‘Toto, I have a feeling we’re not in Kansas anymore.’ congratulations, you are an effective speech to text AI. :)

However, that example is the best, easiest example. Speech audio can vary in quality. Maybe there was background noise which muddied the audio. Our system might have misidentified several sounds or phonemes.
Now the sequence looks like: ‘totoayehaveaelingwherenotinkkansasanymore’
The next difficulty level is our speaker has a different accent and way of saying certain words.
The sequence of sounds now is this: ‘totohiveafelingwhirnotinkkansasanymore’
The early speech to text systems struggled because they tried to match one audio chunk to one sound. If the sounds didn’t match, they didn’t know what was said.
They might have taken our example, diligently tried to match it, and come up with ‘Toto hive feeling whir not ink ansas anymore’
This is where statistics comes to our aid. Instead of just trying to match audio to sounds, the system would also predicts what the sounds are, and what sounds could or should be there.
This is exactly why we need machine learning. (If you don’t understand the term machine learning, might I suggest your read this article then come back)

If a human were trying to write logic to take ‘totohiveafelingwhirenotinkkansasanymore’ and convert it to the correct text, they would have to write thousands or millions of rules.
An example rule could be:
Rule 134: If the sound sequence ‘where’ is followed by the sound sequence ‘not’ there is a 70% chance the correct text is ‘we are’ instead of ‘where’.
This quickly becomes a mess of millions of conflicting rules.
Instead, we give the neural network tons of examples of human speech, labeled with the correct text output, and then train the machine. The machine learns what rules and logic to apply to predict the correct output.
We can think of machine learning as helping in two ways. A neural model is trained to predict the text from speech, or a phonetic transcriber, and the second neural network is a language model, trained to predict text from preceding text. Basically a spelling and grammar checker.
Of course, to train these models, the models need to know how well they are doing. So we need to answer the question…
How are speech to text models evaluated?
There are a lot of metrics that assess speech to text model performance. Some commonly used metrics for evaluating models include:
Word Error Rate (WER): WER measures the percentage of words that are incorrectly recognized by the system. A lower WER indicates better performance.
Perplexity: Perplexity measures how well the STT model can predict the likelihood of the next word in a sequence based on the previous words. A lower perplexity indicates better performance.
Word Confusion Networks (WCNs): WCNs are graphical representations of the STT output that show the possible interpretations of a spoken word based on the acoustic input. Evaluating the accuracy of WCNs can help identify areas where the STT model may be struggling to correctly interpret speech.
These metrics are often used in various combinations.
Let’s look closer at the word error rate.
WER compares the generated text, with the correct human-labeled text. WER counts the number of incorrect words and divides the sum by the total number of words provided in the human-labeled transcript (N).
Incorrectly identified words fall into three categories:
Insertion (I): Words that are incorrectly added to the generated text
Deletion (D): Words that are missing in the generated text
Substitution (S): Words that were substituted between labeled and generated text
Here's an example that shows 3 incorrectly identified words, when compared to the human-labeled transcript:

The formula to calculate WER is to take the 3 types of incorrect words, add them up, and divide by the total number of words.

Let’s use our Wizard of Oz example.
The human labeled phrase of ‘Toto, I have a feeling we’re not in Kansas anymore.’ has 10 words.
If the speech to text generated the text ‘Toto, I have a feeling we’re knot in Kansas anymore.’ we have 1 incorrect word, a Substitution from ‘not’ to ‘knot’.
1/10 = 0.1 * 100 = 10%.
4.7% accuracy is considered closer to human level accuracy, so our system has work to do.
Speech to text is progressing rapidly
It is amazing how far speech to text has come.
What used to cost millions of dollars to develop is now available as free and open source.
Transcribing minutes of footage costs less than a dollar and almost any application or use case where turning speech into text can be valuable, can now accomplish it.
I remember distinctly my sister training Dragon software. She has a learning disability and can’t type well. My parents bought her the software and the microphone, and she would sit for hours reading prompts, and correcting the software when it got it wrong.
Now you can press a button in Google Docs and without training on your voice, Google Docs is better than her program ever was (and it’s free).
Now we need to use this amazing technology!
We will look at some amazing AI tools, go through the various open source libraries you can use to build your own products, and cover the leading companies and APIs providing speech to text services your business can use.
Sources
https://huggingface.co/tasks/automatic-speech-recognition
https://blog.deepgram.com/benchmarking-top-open-source-speech-models/
https://slator.com/how-big-a-deal-is-whisper-for-asr-multilingual-transcription/
https://www1.icsi.berkeley.edu/pubs/speech/audreytosiri12.pdf
https://medium.com/ibm-watson-speech-services/how-to-properly-evaluate-speech-to-text-engines-c90fa902667f
https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/how-to-custom-speech-evaluate-data?pivots=speech-studio
https://computerhistory.org/blog/audrey-alexa-hal-and-more/
https://www.bbc.com/future/article/20170214-the-machines-that-learned-to-listen
https://www.timetoast.com/timelines/the-history-of-voice-recognition
https://www.knowledgenile.com/blogs/what-are-some-of-the-best-open-source-speech-recognition-software/
https://huggingface.co/spaces/evaluate-metric/wer
https://picovoice.ai/blog/top-transcription-engines/
https://medium.com/descript/a-brief-history-of-asr-automatic-speech-recognition-b8f338d4c0e5
https://blog.deepgram.com/the-trouble-with-wer/
https://careers.google.com/stories/how-one-team-turned-the-dream-of-speech-recognition-into-a-reality/