
How to fine tune / train Stable Diffusion using Textual Inversion
How it works, and how to train Stable Diffusion to create your own characters, objects and art styles

Happy New Year! Let’s fine-tune Stable Diffusion.
Text to Image models like Stable Diffusion, Midjourney, and Dalle2 are trained on millions of images.
This training lets the models recognize words and concepts and styles, and ‘draw’ them. The models can draw whatever you want if they have been trained on the thing. They can’t draw things they haven’t been trained to recognize.
For example, if you want to generate images of Matt Damon, Stable Diffusion recognizes Matt Damon because images of him were in the images it was trained on.

But if you want to generate images of a character you invented, a certain scientist character named Mel Fusion… Stable Diffusion has no idea who that is or how to draw her. Since Mel didn’t exist until you created her, there were no training images to use, so Stable Diffusion doesn’t recognize her. This is what Stable Diffusion draws for ‘portait of Mel Fusion, a female scientist in a lab coat’

You can try to use very precise language to describe your character (Mel Fusion, red hair, large blue eyes, slightly upturned nose) but Stable Diffusion still won’t be able to produce the same exact character consistently.

But the awesome thing about Stable Diffusion is it is open source. People have figured out how to train or fine-tune Stable Diffusion to draw whatever they want. This includes art styles, characters, and objects.
This means for example you could create a few of images of Mel Fusion using photoshop or drawing them, then train Stable Diffusion on what Mel Fusion looks like. The result is Stable Diffusion now recognizes and can draw Mel Fusion.

(Yes I know that is Emma Stone, but imagine she was the scientist character you created and had images of 🙂)
There are three main ways to train Stable Diffusion:
Textual Inversion (cheap and good)
Dreambooth (expensive and best)
Hypernetwork (cheap and ok)
We will cover all of them, but at a brief high level, here is how they work.
Textual Inversion - If Stable Diffusion has a vocabulary of words that it understands and can draw, Textual Inversion creates an additional "word" that is added to the base model's vocabulary so it can draw it.
Dreambooth - Dreambooth also creates a new ‘word’ that the model understands, but Dreambooth retrains the entire model, integrating the new "word" and, more importantly, creating connections with other words in the vocabulary so it can draw it combined with other words.
Hypernetwork - Hypernetworks are how Stable Diffusion remembers images you made previously. By training your own hypernetwork, you can basically tell Stable Diffusion that it already generated an image like yours, and push all the results to look like the image it ‘already generated’.
How do the three techniques compare?




All three techniques work.
Textual Inversion seems to be good at style transfers (’in the style of Von Gogh’) and drawing characters as they appear in the training images.
Dreambooth produces more realistic, integrated, expressive and customizable results (this characters as a paper doll). However, Dreambooth is very expensive to run, needing a high level GPU on your computer or renting a GPU from a data center.
Hypernetworks can get your good results but if you overtrain can destroy the image so it just spits out noise.
Since Textual Inversion is cheap and quicker, we will start with it. (We will cover Dreambooth and Hypernetworks in another newsletter!)
Let’s dive into:
What Textual Inversion is,
What are embeddings (important!),
How to train Stable Diffusion using Textual Inversion,
How to use Textual Inversion to create images.
What is Textual Inversion (in depth)
Quick recap on how Stable Diffusion works.
Diffusion Models are trained by destroying training data by adding Gaussian noise, and then learning to recover the training data by reversing the noising process.

Stable Diffusion takes your prompt (’a man as yoda’) as an embedding (we will cover embeddings below), then takes an image of random noise and tries to recover the embedding (your prompt) over multiple steps of removing noise.
Textual Inversion allows you to train a tiny part of the neural network called an embedding, on your own pictures. The Textual inversion training method works by just training embeddings without changing the base model.

image source - https://bennycheung.github.io/stable-diffusion-training-for-embeddings
If none of those words make sense, I would suggest reading our AI terms in 6 minutes guide!

Here is the paper about Textual Inversion that most people use when writing code to do Textual Inversion. - https://textual-inversion.github.io/
So if Textual Inversion trains embeddings, we need to ask, what are embeddings?
What are embeddings in machine learning?
Embeddings are smart compressions of data (images, text, audio, etc) into numerical representations. Embeddings attempt to include all the detail of the original, but get rid of everything else, making them more compact and easier / cheaper to use.
Embeddings are created by sending data into encoders, and getting out a numerical placement of the object in a space, or an embedding.
For example OpenAI recently released a new embedding API. You give it a few words, and it gives you back a set of numbers positioning that group of words into a space.
https://openai.com/blog/new-and-improved-embedding-model/
An example of embeddings is this image which shows Amazon reviews ‘embedded’ into a 2d graph. This allows you to compare the reviews, without having to read and understand each one. I’ll repeat that because it is super important. Embeddings let us compare items, without having to compare the item as a whole.
For example in this image, we can see a cluster of red (negative reviews) and a few more clusters. These reviews say similar things and we know that without having to read them, because we can look at where they were embedded in the space.

Let’s imagine our own example.
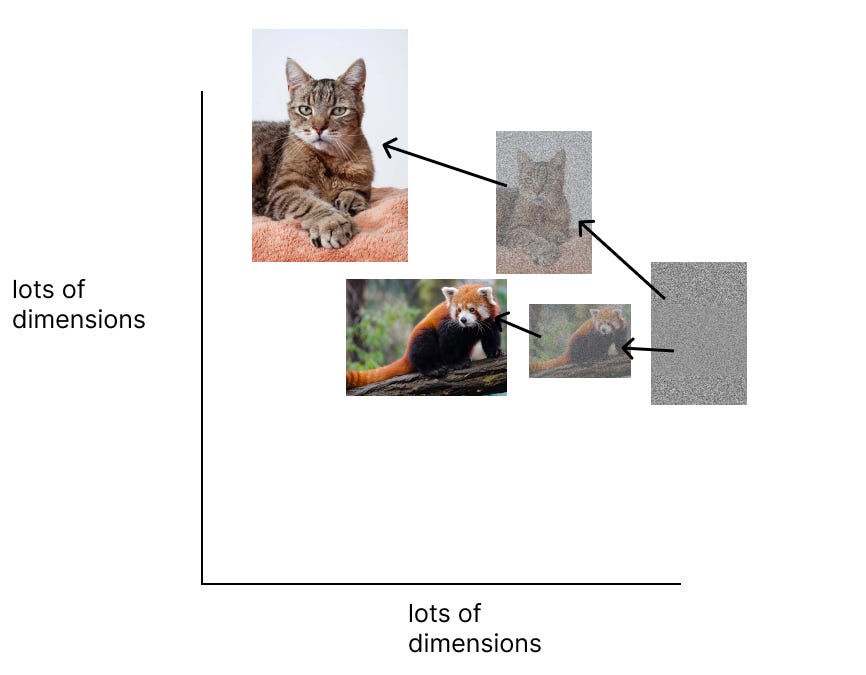
We want to make a neural network that determines how similar an animal is to a cat or a dog.
If a human picked the dimensions to classify the animal on (and in machine learning humans don’t pick dimensions, which is why it is called ‘machine learning’), we could say that we will compare the animals based on two dimensions,
size and
ear shape.
We can represent those two dimensions on a 2d graph. We can put cats in the upper left, as they are smaller with pointy ears, and dogs we put in the bottom right, as dogs are bigger with rounder ears. (yes this is inaccurate with many dog breeds having pointy ears. That is why humans don’t pick dimensions, the machine learns what dimensions work best to compare against 🙂)

Now let’s classify or embed two new animals, a pygmy possum, and a mountain lion.
We take our pygmy possum, and put it into our 2d grid, based on the two dimensions.
The possum is very small so small X value on the x axis, and round ears so very small on the Y axis.
Next we embed our mountain lion. Very large so large X value on X axis, and pointy ears so large value on the Y axis.

By ‘embedding’ the mountain lion and pygmy possum into the 2d space, we can determine, using math, if the mountain lion is more similar to the cat or the dog. For example, if the cat is embedded at (2,10) the mountain lion is embedded at (11,10), and the dog is embedded at (7, 3) we could calculate the distance between each point.
This is important. By comparing numerical embeddings, the model can decide how similar the mountain lion is to the cat, without ‘knowing’ about either. It just knows where it is embedded in the space.
You might notice it is hard to determine how similar a random animal is to a cat or a dog just using the two dimensions of ear shape, and size. That is why real machine learning models use thousands or millions of dimensions to compare items. The computer determines the dimensions. It might be color, eye shape, paw shape, tail structure, nose color and on and on, millions of dimensions. It is hard to draw multi-dimensions space, which is why most examples of embedding are 2d or 3d, but a true embedding is the object embedded into a multidimensional space using thousands or millions of dimensions. But luckily in that space which is hard to visualize, we can still use math to compare them.
So how does Stable Diffusion use embeddings?
When you train Stable Diffusion using Textual Inversion, you are basically adding a new point to the graph, a new word or concept embedded into the space.
If you wanted Stable Diffusion to be able to draw a red panda, and Stable Diffusion didn’t know how, you could train it on a few images of a red panda and it would create a new embedding of it.

Stable Diffusion starts with noise, and then tries to get closer to the text embedding of your prompt. By training new embeddings for Stable Diffusion, you can give it a new point to try to get close to as it removes noise. This allows Stable Diffusion to create red pandas, or specific styles, or any character you can imagine.
Now that we understand what Textual Inversion is doing, lets figure out the nuts and bolts of actually using it.
How to use Textual Inversion
The good news, is that once someone has trained a Textual Inversion model and shared it, anyone can use it.
The result of textual inversion training is a .pt or a .bin file with the embedding and info included in that file.
Nice people have made lists of textual inversion models that you can download and use.
https://cyberes.github.io/stable-diffusion-textual-inversion-models/
https://huggingface.co/spaces/sd-concepts-library/stable-diffusion-conceptualizer
To use a file generated by someone else you:
Check if your version of Stable Diffusion supports using embeddings.
Download the textual inversion model file
Put the file into the folder or location where your version of Stable Diffusion is looking for embeddings.
Use the embeddings filename in the prompt.
Let’s use a real example. You want to generate images that look like the Netflix show Arcane.

You can use Textual Inversion to make a model trained on images from the show.
But someone already did!
Download the file
Put it where your Stable Diffusion can find it
Generate an image using the token ‘arcane-style-jv’ in the prompt. Something like ‘A woman holding a torch in the style of arcane-style-jv’
This is the result:

Looks like Arcane!
So now that we know how to use the textual inversion model, how do we train our own?
How to train using Textual Inversion
If your computer is not super old, most likely you can train Textual Inversion as it is cheaper and requires less power and memory to run.
How to Train Textual Inversion on Windows or a Mac
There are many programs that can do it, but Automatic1111 is a great one.
This article explains how to do it.
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion
In a nutshell you:
gather a few images of what you want to train it on,
run them through a pre-processor to make sure they are the right size and have a label,
create the token name (how you will reference the thing you are training),
then run the training command
If it works it will create a .pt file with your training data inside which you can use or share.
Note about training textual inversion on a Mac.
I have a Mac and I haven’t figured out how to get Textual Inversion working yet. This issue shows others have gotten it to work https://github.com/invoke-ai/InvokeAI/issues/1887 but personally I have had issues.
But luckily, anyone can train Textual Inversion from any computer by using a Google Collab.
This YouTube video as of Jan 2023 is the most up to date Textual Inversion training video out there.
How to train Textual Inversion using Google Collab
This video walks through how to do it.
Here are the links to two Collab notebooks that allow you to train:
In a future newsletter, we will dive into how to train Stable Diffusion using Dreambooth and Hypernetworks.
Let me know if you have any questions or if I got something wrong.
Thanks for reading!
Hey mate, for Macs you can follow this tutorial, but you also need to do one more thing:
https://www.youtube.com/watch?v=2ityl_dNRNw&list=WL&index=3&ab_channel=Aitrepreneur
When starting, add this at the end:
./webui.sh --no-half
I'm using Automatic1111 for training embeddings, and Kohya for training LORAs, on my M1 Mac with 64GB. Feel free to reach out on Twitter @andupotorac if you get stuck. Happy to help!