
Text to 3D - Where is Midjourney for 3D models?
Short answer, not here yet, but we have several proof of concept papers and exciting developments

Imagine being able to type ‘friendly commuter train’ as a prompt and get a fully rendered 3D model back.

You could then use that model in any 3D program, explore it in VR, or 3d print it.
That is the promise of text to 3D.
Currently, video games, VR, AR, and movies use thousands (millions?) of detailed 3D models. These 3D models are handcrafted by very talented artists by hand in software like Blender (free) and Maya3D ($$). Creating, texturing, lighting, a 3D model is a difficult process and takes a lot of time.
Becaue of the magic of the internet and the fact that you can replicate digital items for basically free, you can buy a model of a train for $16 dollars or so on many 3D model marketplaces.
But what if you want a different style of train, or different shaped windows? Unless an artist already made it and listed it for download or sale, you would need to learn Blender and create the train you want yourself.
Text-to-3D generative models could change this process entirely. You would be able to describe in words the 3D model you want, and the AI would create it.
This would lower the barrier to creation for novices, and improve the workflow of artists.
When anyone can get a 3D model by describing it, the world changes.
In this episode of Mythical AI, we are going to learn about:
what a 3D model actually is,
Three proof of concept text to 3D models (DreamFusion, Magic3D, Point-E)
a look at what is coming soon

What is a 3D model?
A 3D model is a file that described a mathematical, coordinate-based representation of an object in three dimensions.
Let’s imagine the object we want to create is a simple box.

We need to tell the computer what the object is, what its shape and structure are, and where the box exists in space.
To describe where something is in space, we commonly use coordinate systems. The 2D, XY coordinate system is super common (don’t worry if you didn’t love math class, this math section will be quick and useful to understand what the AI tools are actually doing).

We use two numbers, a X number and a Y number to describe where a point is. The green point in the image above is at 2 on the X axis, and 3 on the Y axis.
But if we only used the XY coordinate system to describe our box to the computer, the box can only be flat.
We need to add the 3rd dimension (3d get it?) or Z axis, projecting up out of the flat XY grid, going out 90 degrees from both X and Y axis.

Now using X, Y, and Z, we can place a point anywhere in our 3-dimensional or 3D grid. To make a box we need to describe the 8 points that make up each corner in 3D space.

Once we have those points in our 3D model, we need to connect certain points to make actual shapes.
We connect two points, to get a line.
Connecting three or more points creates a face.
Edges are where two faces meet.
Vertices are where three or more edges meet.

So our simple example box from the beginning can be represented by a 3D file, which has a bunch of numbers and relationships between those numbers. The box shape is created by 8 points in XYZ space, 12 lines connecting those points, 6 faces from points connected, 12 edges where those faces meet, and 8 vertices where faces meet.
It is a lot to remember, luckily computers are good at math and can remember and display 3D files instantly.
One additional note, since most 3D objects are not just made of boxes, the basic unit of a 3D model is not a square, but a polygon. A polygon is a plane figure with at least three straight sides and angles.
By connecting 3 or more points we form a plane which is a polygon.
As a 3D model incorporates more and smaller polygons, more detailed, intricate and lifelike textures and curves can be created.
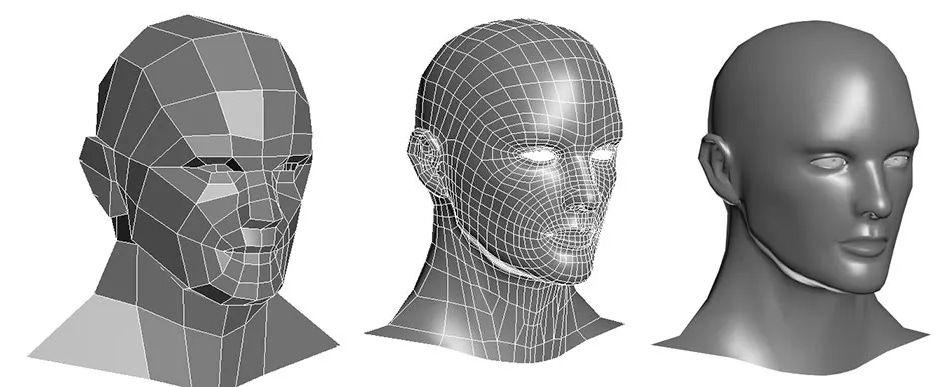
How are 3D models currently created?
In the early days of 3D modeling, programmers had to calculate and enter coordinates of points and lines by hand.

Luckily for everyone, software was created to allow people to draw squares and polygons and the computer would automatically track the coordinates of all the points and their connections.
A modern example of that 3D software is Blender, a free powerful open-source 3D modeling program anyone can use to create just about anything.

However, 3D modeling still has a sharp learning curve and takes a long time.
The dream of text to 3D AI is a user could describe the model they want using text, and the AI would do all the 3D modeling for them.

Unfortunately, the mythical AI model and process to create 3D models automatically from text don’t exist quite yet.
Google, NVIDIA, and OpenAI all released papers one month apart, which show ‘proof of concept’ models. These early yet impressive demonstrations show the early stages of this text to 3D dream.
The 3 proof of concept models are:
Dreamfusion - Google
Magic3D - Nvidia
Point-e - OpenAI
Lets dive into each one.
Dreamfusion - Text to 3D

Dreamfusion is a proof of concept paper that Google released in Sept of 2022 showing how they can take a text prompt describing an object and turn it into a 3D model.
How does Dreamfusion work?
Dreamfusion takes your prompt and first generates 2D images of the requested object using Google’s (not public ) Imagen text-to-image diffusion model.
They append "front view" and "back view" to the object to get different images of the object based on the azimuth (0 - 360 degrees rotation) and elevation (180 degrees up and down).
They then put those images into a NeRF (we will cover NeRF in a future Mythical AI episode!) which generates a 3D model.
The generated NeRF models can be exported to standard 3D format (STL or PLY) meshes using the marching cubes algorithm.
The resulting 3D models can be used in any 3D software.
Is Dreamfusion public (aka can we use it yet)?
No, Dreamfusion is not public. Google announced it September of 2022 and there hasn’t been any further development.
Magic3D text to 3D
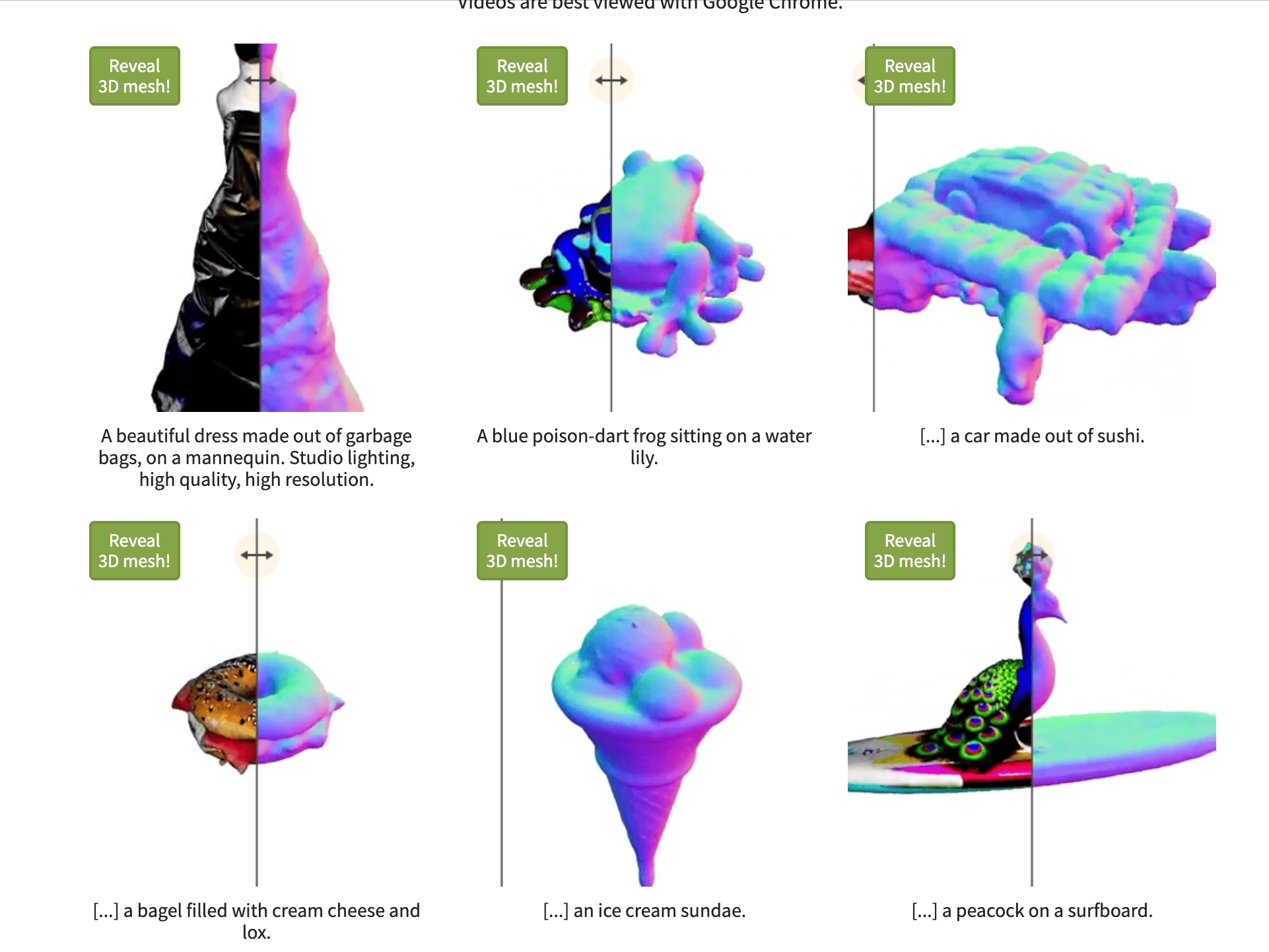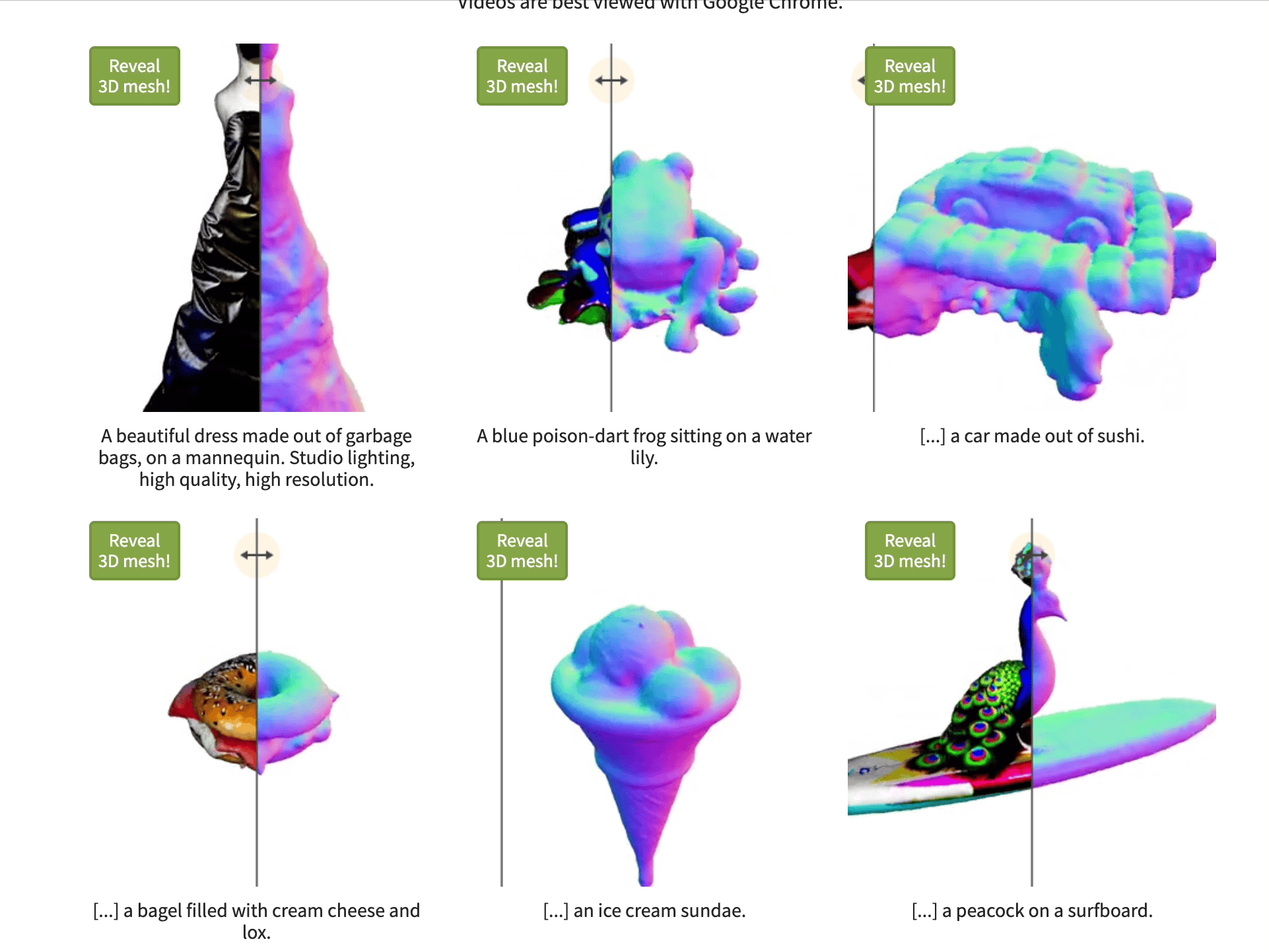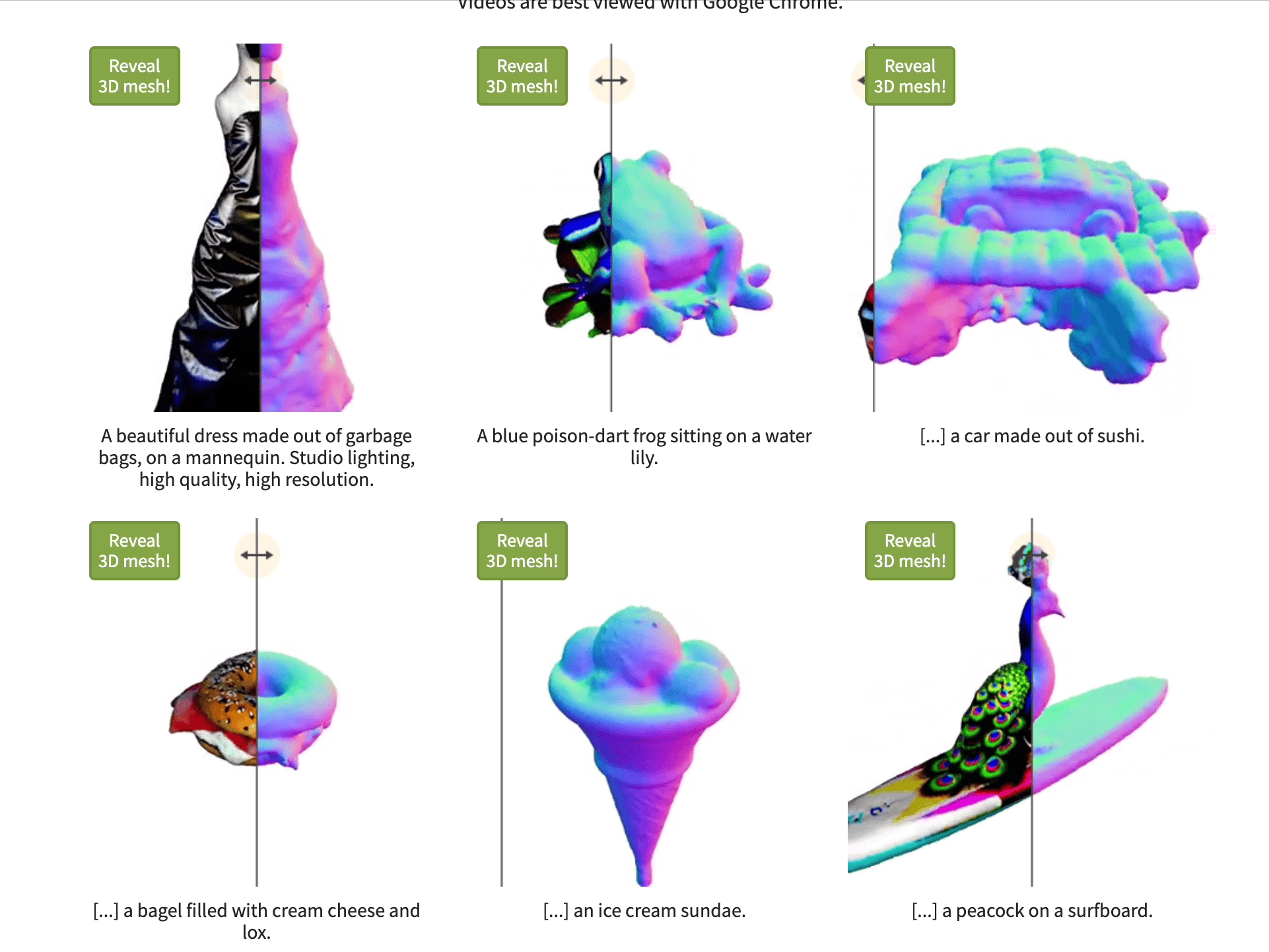
Magic3D is a proof of concept paper released by Nvidia in Nov 2022.
How does Magic3D work?
Magic3D uses eDiff-l (unreleased Nvidia image generator) to create low-resolution images of the object prompt.
They then repeatedly create low-resolution images from different angle of the object, which they feed into a system that updates the 3D model each time.
They then pass the rough 3D model to DMTet (unreleased Nvidia 3D model generator) to generate a high quality 3D model.
They then generate images of this higher quality 3D model, and pass those back through an image generator to upscale and enrich, and then apply those to the 3D model. This effectively upscale the model like you would use an AI image upscaler.
Magic3D claims to synthesizes 3D content with 8× higher-resolution than DreamFusion while also being 2× faster. We can’t test that since neither model has been released publicly.
Is Magic3D public (aka can we use it yet)?
No, Magic3D is not public. Nvidia announced it Nov of 2022 and there hasn’t been any further development.
Point-e

Point-E is proof of concept paper and code that OpenAI released in Dec of 2022 showing how they can take a text prompt describing an object and turn it into a 3D point cloud.
Point-E is not yet as good as Google’s DreamFusion or Magic3D as the quality of the models is much lower. However, the generator is faster than DreamFusion, being of approximately 600 quicker to generate than DreamFusion.
How does Point-e work?
The OpenAI group built a collection of several million 3D models and exported it from Blender. They then generated a point cloud from these renderings to represent the 3D object’s density of composition.
They processed the data more and put it into their GLIDE model (diffusion generator similar to Dalle) to train.
Point-E takes the prompt and starts with a random shape which gradually transforms it from the random shape to the desired one, guided by the prompt.
This low resolution output is then sent into a point cloud upsampler, enhancing the final product’s quality. Blender is then used to transform the point clouds into meshes of polygons, making them usable in most 3D modeling programs.

You will notice that Point-E output is very different from the NeRF generated by DreamFusion, and the model generated by Magic3D. This is because the points are not connected into lines, planes and polygons. They can be connected later but they are generated as individual points.
Is Point-e public (aka can we use it yet)?
Yes, the Point-e code has been made public. https://github.com/openai/point-e
What is the future of Text to 3D?
It is almost certain that in the near future, we will be able to describe 3D models and AI can create them.
More and more papers, and early products in this space have continued to be released since the 3 proof of concept papers.
Here are the most 5 exciting papers:
LumaLabs is working on text to 3D product - https://captures.lumalabs.ai/imagine

This paper, https://threedle.github.io/3DHighlighter/, show how you can select areas of a 3D model using text.

This paper, https://bluestyle97.github.io/dream3d/, shows additional work on more accurate Text-to-3D Synthesis, Using 3D shape prior and Text-to-Image Diffusion Models.

This paper, https://datid-3d.github.io/, show additional gains on text to 3D models focusing on human faces.

And this paper shows Image to 3D, https://vita-group.github.io/NeuralLift-360/, taking a photograph of an item and generating a 3D model based off of it.

I think before 2023 is complete, we will have access to a basic usable text to 3D model.
Thanks for reading. Let me know in the comments if I missed anything. See you next week!
Thanks for your explanations Josh, great Issue. I am honest: I am fascinated by this crazy AI thing nowadays, but I see we are going sooo fast, so fast everyday there something bigger than the day before. Aren't we going too fast? :)