
Where is the Midjourney or Dalle2 for creating music from text prompts?
Enter text, get music. Why isn't it here yet?

Imagine entering the prompt ‘Mozart’s Eine kleine Nachtmusik in the style of Taylor Swift’ and getting something like this beautiful piece of music (gets going 11 seconds in) but the music is created entirely by a computer.
It seems like this should be possible. After all, if you can enter the prompt ‘Taylor Swift sitting at a piano as a classical composer portrait, highly detailed, oleo painting, artstation, concept art, sharp focus, illustration, art by Caravaggio and Rembrandt and Diego Velazquez’ and the computer can create this:

Why can’t we create the same for music as well? Where is Dalle2 model or Stable Diffusion model for music?
First, what is Dalle2 for music?
We need to define our terms. Dalle2 lets you:
enter text, and
get images out of ‘thin air’.
So ‘Dalle2 for music’ would let you:
enter text, and
get music out of ‘thin air’.
Simple enough. And while there are lots of amazing AI music tools, (including my favorites I have listed some of them at the end of this post) there is no tool currently available that lets you enter text and get music.

(Image source - Paid article)
A majority of the current AI tools take existing audio and make it better or enhance it. The current tools enhance artists ability, help with writing lyrics, producing music, or creating it. No tool lets the average person make music from a text box prompt.
But what about all the ‘songs written by AI’?
There have been many songs produced with the help of AI. Some songs claim to be written ‘only with AI’. For example this AI created Eurovision song, is a famous one with millions of views.
But this song was not created by an AI out of thin air. The creators trained models on hundreds of songs, took the results, evaluated the chunks, then combined all of the best pieces.
It would be more like if a team fed prompts to Dalle2, took the results, chopped up their favorite chunks, then recombined them with Photoshop. The list of people involved reads more like movie credits:
Concept and Creative direction by Nimrod (Nim) Shapira (nimshap.com) Construction and Production by Allenby Concept House (allenby.co.il) Co-produced by Nimrod (Nim) Shapira Song production: Song Curation by Amir Shoenfeld Song Production by Avshalom Ariel Additional song curation by Ben Scheflan, Nim Shapira, Avshalom Ariel and Eran Hadas Background vocals by Avshalom Ariel and Ben Scheflan Mix by Omer Schonberger Mastering by Jonathan Jacobi Recorded at Jaffa Sound Arts Music video team: Directed by Karni and Saul @ Sulkybunny (sulkybunny.com) Title design by Adam Blufarb Illustrations by Eliran Bichman Deep Learning team: Lyrics generation by Eran Hadas AI and ML Team: Oracle Innovation and Oracle Cloud Asaf Sobol - Senior Business Development leader, Oracle Israel Andy Welch - Innovation engineer, Lead data scientist, Oracle UK Asaf Lev - Senior Innovation engineer, Oracle UK, Ireland & Israel David Cottee - Senior Director of Innovation, Oracle UK, Ireland & Israel Midi conversion and Music consultation by Micha Gilad Additional Midi conversion by Ann Streichman Legal consultancy: Attorneys Sally Gillis and Shirley Gal from Eitan, Mehulal, Sadot.
Other examples of AI created songs include the Lost Tapes of the 27 Club, and Beethoven X but in all cases, the AI was feed training music, recognized patterns and similarities, created samples, which humans then curated, assembled, and performed to create the music.
As of right now Nov 2022, a text to music from thin air model like Stable Diffusion or Dalle2 or Midjourney does not exist for music.
This leads us to the question of why?
Why Dalle2 for music doesn’t exist (yet)
From my research, here are some of the reasons why we don’t yet have a text to music generative model.
Problem 1 - Lack of data
Text to image models are trained on dozens of terabytes of data. We don’t have the same amount of public training data for music yet.
Spotify says they have 30 million songs. Someone calculated that is 200 terabytes. So the entire library of Spotify is the size of some soon to be released image models training dataset.
Dalle2 was trained on 650 million images.
Stable Diffusion was trained on a set of 2.3 billion images
A quick graph to visualize how much bigger the training sets of text to image models are:

It is not an apples to apples comparison, but a real world example help. This research project trained their music generating models using 170,000 piano roll songs in a public dataset which is 4.2 gb in total. That is 0.0042 of a terabyte or less than half of one percent of the amount of training data generative images models are using.
In deep learning and machine learning, more data often equals better performance, and for music models, the data is lacking.
Problem 2 - Lawyers
Lawyers have more power in music than in any other creative industry. If you need an example take a look at YouTube.
Someone can spend hundreds of hours creating an incredible video, and if they include mere seconds of a song, the music label can effectively claim the entire video, meaning all advertising revenue from that video goes to the record label. In the current copyright law landscape, seconds of song are worth more than hours of video.
This has a chilling effect on AI music research. Lots of researchers and companies fear that they could spend a ton of time and money training models, only to have the major Music Publishers and their packs of legal teams coming after them.
Problem 3 - Music is more like video, than it is a still image
An image is essentially a 2d collection of points. You could argue that each pixel contains 3 numbers indicating the brightness of the 3 colors of pixels, but it is still a grid of numbers.

An equivalent musical pixel could be a collection of sine waves.

200 years ago Joseph Fourier gave us the insight you can combine a set of pure sine waves ( each with their amplitude and phase shift ) to synthesize any possible sound. This is how your computer can play the sound of a beetle, or The Beatles. It is just combining different sine waves.
But music adds the dimension of time. A music generating AI doesn’t need to just combine a bunch of sine waves once. It needs to do so thousands of times per second over the course of minutes.
An AI that generates videos needs to create 24 (or more) images a second.
Music AIs need to generate thousands of samples per second. For example, a standard mp3 has 44,100 samples per second.

Just like videos are harder to create than still images, music is harder to create than a short audio sample.
Problem 4 - Music takes longer to consume
If I show you these 4 AI generated images of Link, how long does it take to pick your favorite?

It takes a few seconds perhaps?
If I asked you to listen to four, 1 minute songs, how long would it take you? At least 4 minutes. Because music happens over time, it takes time. In the 1 minute it takes you to listen to a song, you can browse hundreds of images.
Music is more difficult to consume, to browse than visual images. This makes it harder to evaluate the results of a system, and tune it to produce better results.
Problem 5 - Digital instruments are worse than real world instruments
Synthesizing real instrument sounds using software is still difficult. When you hear a guitar created digitally, it still doesn’t sound like the real thing.
The best software instruments not open source, and are protected by the $3B music software industry.
Most AI music projects are using open-source or self-developed instrument sounds, and they compare in quality to the best software instruments. And the best software instruments don’t compare to live instruments recorded in a studio. Instrument sound quality changes how music sounds and feels. The arrangement of notes could be incredible, but if the instruments sound bad, and we think the music is bad. (Maybe because it is?)
Problem 6 - We are most strict in our evaluation of music
Perhaps because listening to music is in investment of time, or music has greater power to make us feel something, we are also less forgiving in our judgement of music.
You can look at this AI generated picture of a princess and think, yep that is pretty good. Even with the messed up hands and the slight incorrect placement of the eyes.

But a few wrong notes in a music piece makes it overall trash.
Problem 7 - Music is more subjective
Music inputs are more subjective than visual inputs. You could show 10 people an image of Einstein and most would agree ‘yes that image is Einstein’
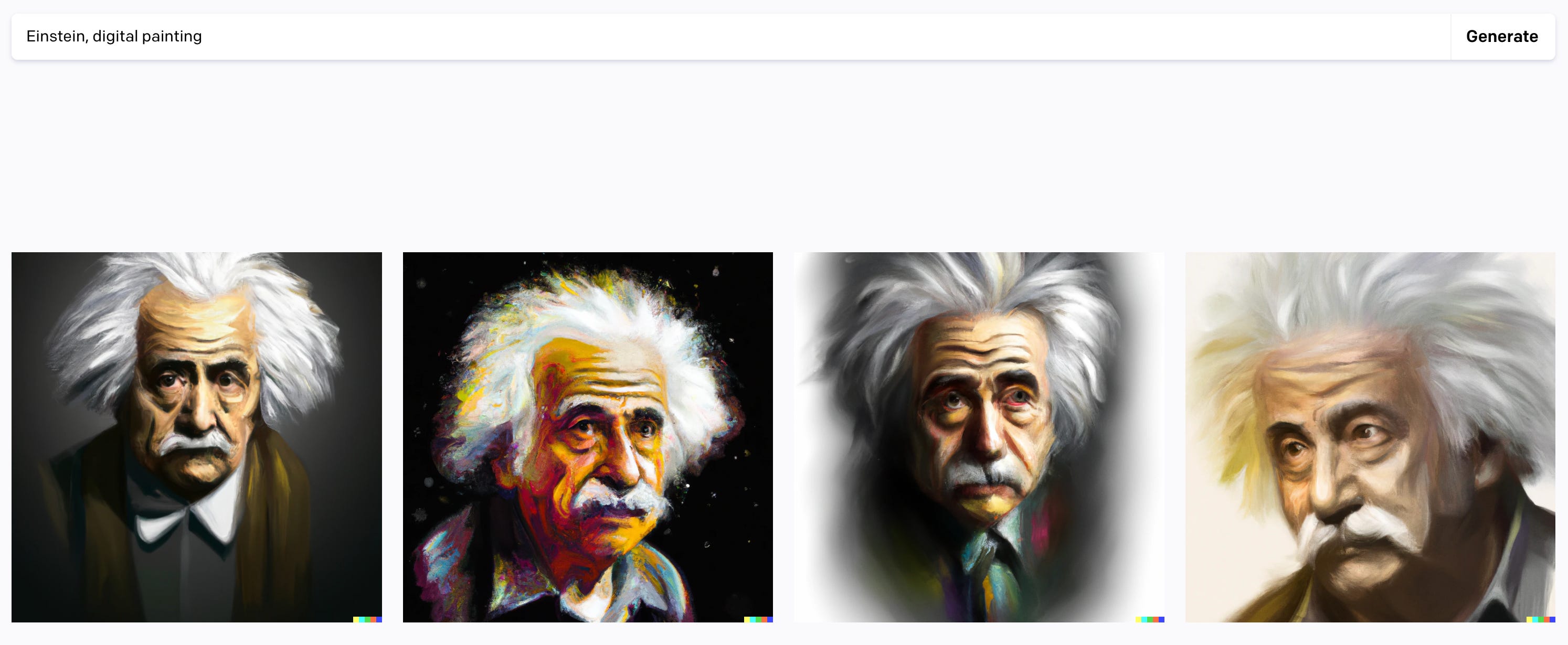
You would probably get wide agreement on if the image is a ‘good’ image of Einstein or not as well.
But play a song for 10 people and ask them to describe it, and you could get 10 different descriptions.
This 9 second clip 👇🏻 has been described as ‘dreamy, hopeful, chill, beats’ and so on.
If humans can’t even agree on standard definitions of songs, how can an AI create a song to meet those shifting definitions.
Problem 8 - Lyrics are an additional difficulty layer
Music also has the tricky problem of it often includes lyrics.
Add lyrics into the problem space, and now the AI doesn’t just have to learn to create sounds, it also has to be able to create text that has rhythm, and rhyme, makes sense, and has a specific vibe.
While there are projects and programs that create lyrics, none of them are very good yet.
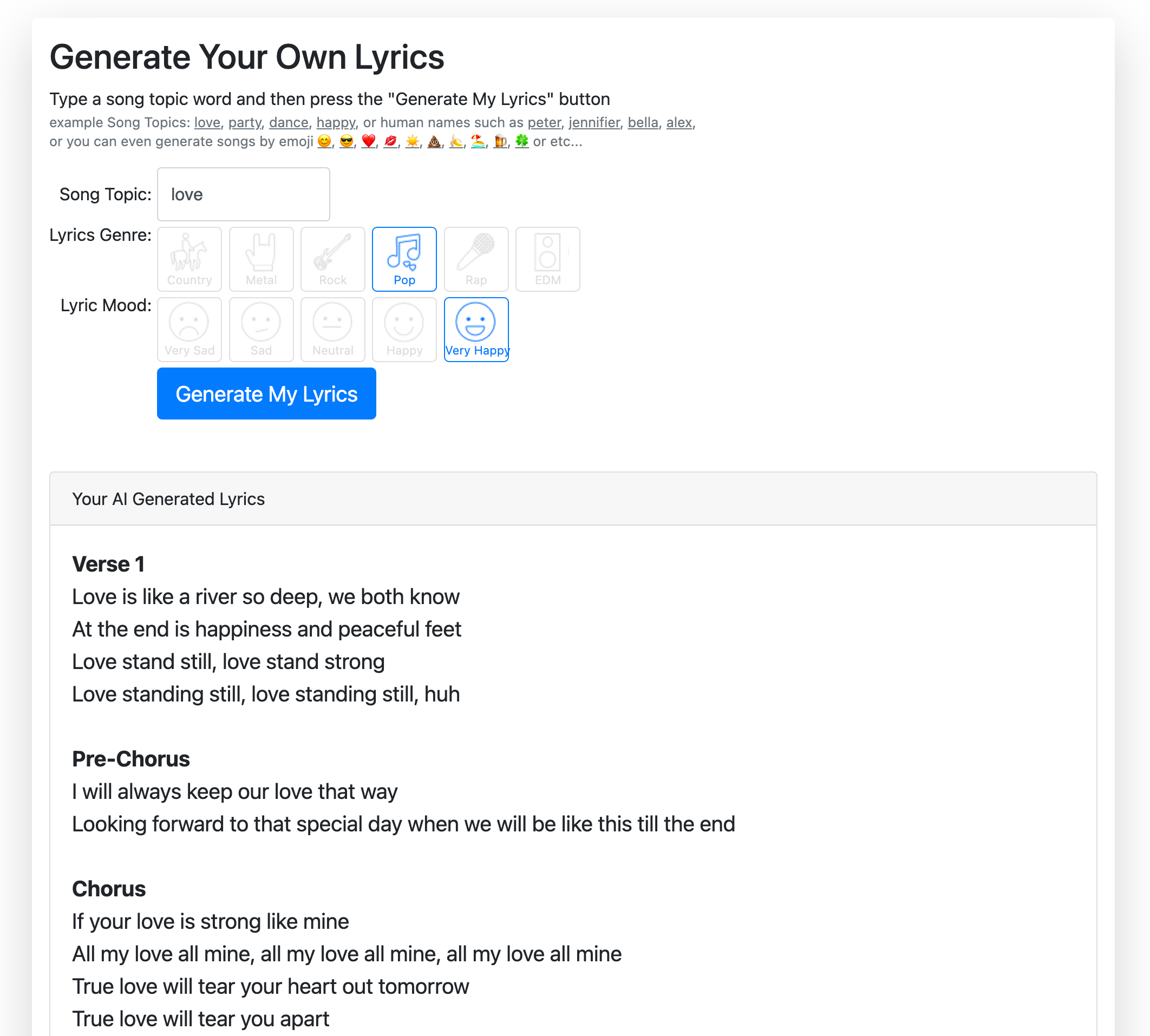
And people have been working on this problem for a long time. David Bowie tried to create a lyric composing program called the Verbasizer in 1995.
While there are problems…
All of the reasons above mean music AI/ML models have less data to train on, take longer to run, are more expensive to run, have only ok sounding output, and produce output that is harder to judge the quantitatively.
You could look at these issues and ask yourself, will we ever get a generative AI model for music? I think 100% yes.
We will get a Dalle2 for music, and soon
You could have written a similar article a few years ago explaining why AI would never be able to take a written text description and turn it into an image.
And yet here we are, with three amazing tools in Dalle2, Stable Diffusion, and Midjourney doing just that.
With the speed that AI is progressing, I wouldn’t be surprised if we have a Dalle2 for music in less than 2 years.
There are already projects that seem to be making progress including:
Jukebox and MuseNet (from the creators of Dalle2)
However, all of the above tools are not publicly available, or require knowledge of machine learning, training, or at least Python to use currently.
So what AI Music Tools can we use right now?
There are lots of fun AI music tools that you can use right now. These break down into 2 sections based on how much music knowledge you need to operate them.
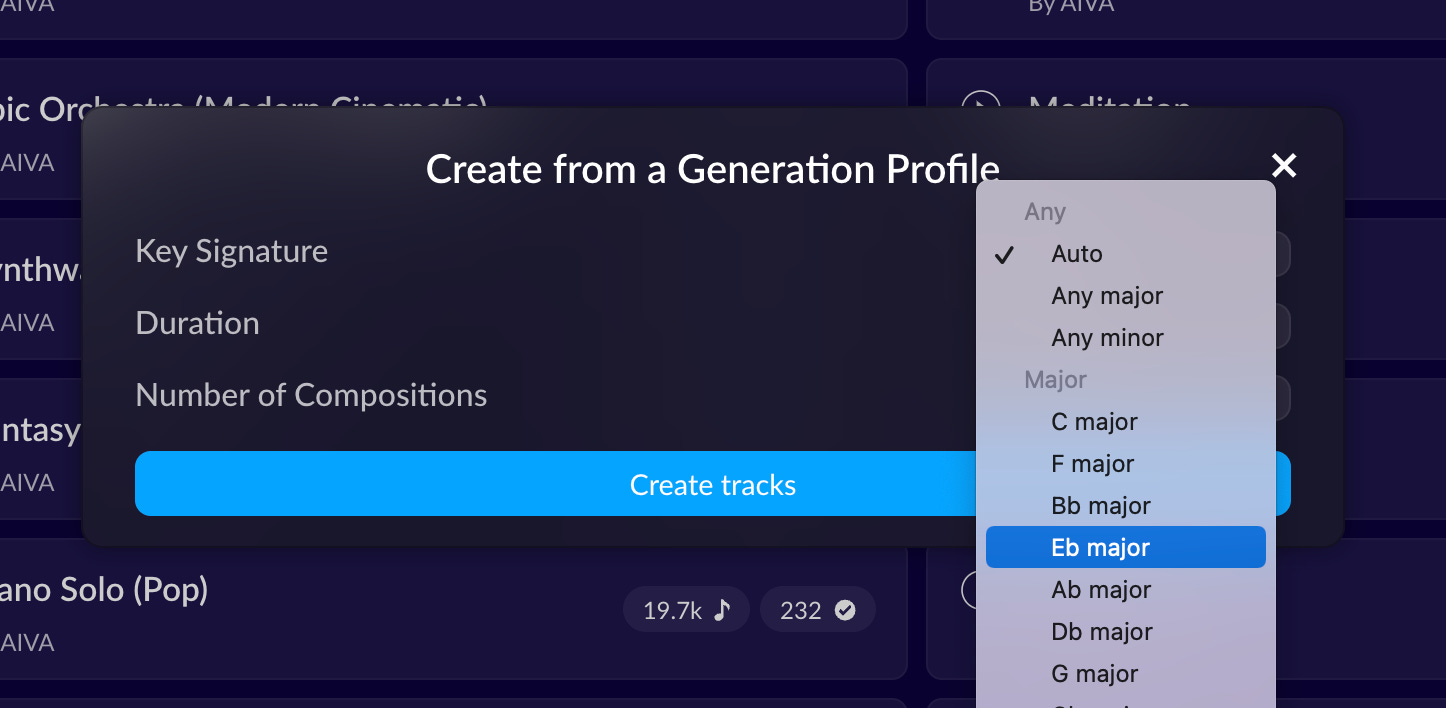
Push button tools (no music knowledge required)
These tools you can pick from several parameters. Key, duration, mood, and they will generate music for you. Just like you don’t need any knowledge of painting to use Dalle2, these tools will create music without requiring musical knowledge or skill.
Music Creation Tools (music knowledge required)
These tools can help musicians with some level of skill and knowledge create music. Some integrate with popular Digital Audio Workstations or DAWs and some are stand alone apps.
Any tools you love that I missed? Reply to this email and let me know.
Thanks for reading.
Sources
https://ai.googleblog.com/2022/10/audiolm-language-modeling-approach-to.html?m=1
https://towardsdatascience.com/generating-music-using-deep-learning-cb5843a9d55e
dog